Algorithm
Consider the linear regression with samples 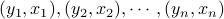 satisfying:
satisfying:
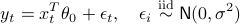
Here 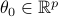 is an unknown parameter vector relating the covariates
is an unknown parameter vector relating the covariates 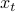 to the response
to the response 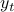 , and
, and 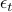 are noise terms. ‘‘The covariates are potentially collected adaptively, and so can be correlated to prior covariates
are noise terms. ‘‘The covariates are potentially collected adaptively, and so can be correlated to prior covariates 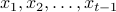 .’’
.’’
Goal: We aim at ex post statistical inference on individual model parameters 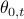 , in terms of frequentist p-value and confidence interval.
, in terms of frequentist p-value and confidence interval.
Method
Below we provide a brief explanation of the online debiasing method. For more details and scissions, we refer to our paper.
Denote by 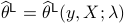 the Lasso estimator
the Lasso estimator
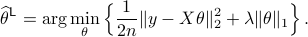
The online debased estimator 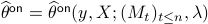 takes the form
takes the form
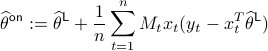
The term ‘online’ comes from the crucial constraint of predictability imposed on the sequence: there exists a filtration 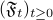 so that, (1) are adapted to
so that, (1) are adapted to 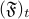 and is independent of
and is independent of 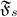 for
for 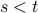 . We assume that the sequences
. We assume that the sequences 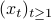 and
and 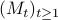 are predictable with respect to
are predictable with respect to 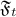 .
.
How to choose decorrelating matrices?
We focus on times series as an important application of adaptively collected data and consider a vector autoregression (VAR) model for time series. By a proper change of variables, a Var(d) model can be represented as the linear regression with 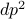 parameters and
parameters and 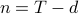 sample size where
sample size where 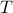 is the time horizon where we observe the times series, and
is the time horizon where we observe the times series, and 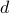 is the lag. Our primary interest is in high-dimensional Var(d) model, where the number of model parameters exceeds the sample size .
is the lag. Our primary interest is in high-dimensional Var(d) model, where the number of model parameters exceeds the sample size .
The proposed online debiasing provides valid statistical significance measures for the model parameters (the time invariant matrices in the Var(d) model).
To construct decorrelating matrices 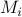 that satisfy the predictability condition, we proceed as follows:
that satisfy the predictability condition, we proceed as follows:
For given positive integer numbers
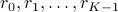 that add up to
that add up to 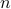 , we partition the time horizon into episodes
, we partition the time horizon into episodes 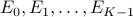 , with
, with 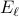 of length
of length 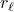 and let
and let 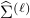 be the sample covariance of features in the first
be the sample covariance of features in the first  episodes.
episodes.
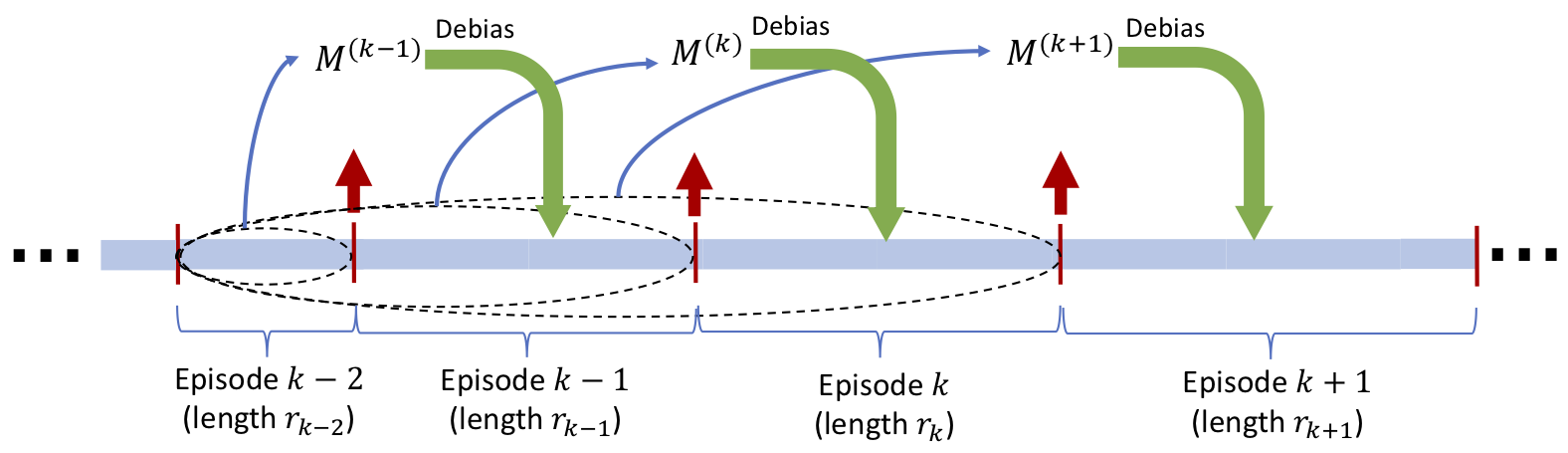 |
At the beginning of each episode
, we calculate a decorrelating matrix 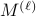 using the previous data points and use that matrix to debias the sample coming in the current episode, that is to say
using the previous data points and use that matrix to debias the sample coming in the current episode, that is to say 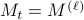 for
for 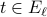 . The details of this step are summarized in the box below.
. The details of this step are summarized in the box below.
1. For 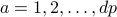 do
Construct
do
Construct 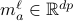 by solving the following optimization:
by solving the following optimization:

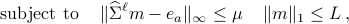
With 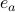 the standard basis element with one at the
the standard basis element with one at the  -th position and zero everywhere else.
-th position and zero everywhere else.
2. Set 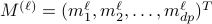 . In words, stack the constructed vectors
. In words, stack the constructed vectors 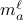 as rows of .
as rows of .
Our analysis in the paper suggests the choice of episode lengths 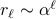 . The code can take the parameter
. The code can take the parameter 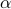 as an input.
as an input.