|
The Hanley and Hoberg emerging risks database is based on a major
computational linguistics project that was funded by NSF Grant #1449578. The project also benefitted from text
analytic tools and expertise provided by metaHeuristica LLC. Research Abstract We use computational
linguistics to develop a dynamic, interpretable methodology that can detect
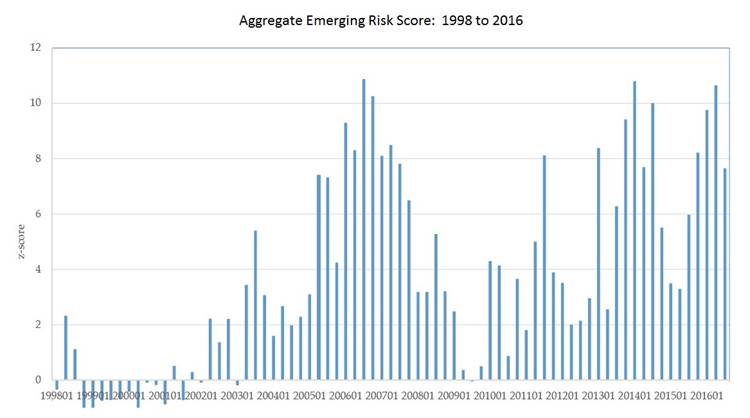
emerging risks in the financial sector. Our model can predict heightened risk
exposures as early as mid-2005, well in advance of the 2008 financial crisis.
Risks related to real estate, prepayment, and commercial paper are elevated.
Individual bank exposure strongly predicts returns, bank failure and return
volatility. We also document a rise in market instability since 2014 related
to sources of funding and mergers and acquisitions. Overall, our model
predicts the build-up of emerging risk in the financial system and
bank-specific exposures in a timely fashion. [Download Complete Research
Paper] Brief Summary of Methods The emerging risks database
is based on risk factor disclosures parsed from bank 10-Ks, which are then
processed using two text analytic tools in tandem. The text-based risk factor data is based
solely on 10-K risk factor disclosures made by publicly-traded US Banks. This
data is extracted from 10-ks using metaHeuristica’s
high-speed database to precisely extract annually updated risk factor
disclosures for each bank from 1997 to present. Separately for each year, we then run metaHeuristica’s integrated topic modeling module to
obtain a 25-factor Latent Dirichlet Allocation
(LDA) model, which we use to extract 625 bigrams (top 25 from each risk
factor). Because LDA puts high probability weights on bigrams that are
present in the risks disclosed by many banks, these 625 bigrams are systemically
important and not idiosyncratic.
Finally, the bigrams are fed into metaHeuristica’s
semantic vector technology, which uses a neural network to generate a vector
space model. This final step extracts
interpretable vocabularies that define each economically meaningful
bigram. We then score each bank to
determine its final risk exposures using simple cosine similarities. Please see the research paper referenced on
the right for all methodological details (above is a very brief summary
only). We use these methods to
construct two emerging risk models.
The first is a static risk model, where the candidate risks are
selected based on the existing literature on fundamental risks. In this model, the risks are held fixed
during the entire sample. The second
is an automated dynamic model where the 625 unique bigrams extracted above
are filtered down to a set that is free from multicollinearity, economically
relevant, and economically interpretable.
In this model, the number and the list of risk factors varies from
year to year.
Hanley
and Hoberg Data Library
|
|